-
CUDA的线程组织结构
略,见CUDA八股文 -
CUDA的存储体系结构,每一种存储的优缺点,该如何合理使用。
就是层级内存,小快vs大慢,细节见见CUDA八股文 -
GPU每一代的新特性有了解过吗?应该从哪里去了解详细信息?
- Tesla(2006)→ Fermi(2010)→ Kepler(2012)→ Maxwell(2014)→ Pascal(2016)→ Volta(2017)→ Turing(2018)→ Ampere(2020)→ Hopper(2022)→ Blackwell(2024*)
- Volta - tensor core,其他不太了解
- 看nvidia 架构白皮书 Optimize Data Center Infrastructure Solutions | NVIDIA
-
CUDA stream的概念,为什么要使用多个stream?
- 主机发出的在一个设备中执行的 CUDA 操作,包括主机-设备数据传输和 kernel 执行
- 充分利用资源/重叠加载和计算
-
GPU和CPU分别适合执行哪些程序?结合它们的硬件架构解释一下为什么它们有各自的优势。
GPU = (CPU 核 - 分支预测/多层cache/核频率) x n- GPU适合执行:数据密集逻辑简单/高度并行化的任务,核心多但每个核心缺乏高级功能,有高内存带宽,时钟频率低
- CPU适合执行:单线程+分支复杂,因为核心少,但核心的分支预测乱序执行流水线功能强,缓存多,时钟频率高
-
说明一下神经网络加速器与CPU、GPU的区别,他们各自有何优势?
ASIC/FPGA/TPU...
能耗比高,为特定操作优化,适合推理任务 -
半精度浮点数FP16各个部分的具体位数,为什么要有半精度浮点数?
1+5(指数)+10(尾数)
for 深度学习运算,牺牲精度以换取运算速度,减少计算/内存/带宽消耗 -
TensorCore的加速原理
- 专用硬件
- 混合精度,减少计算/内存/带宽消耗
- MMA指令,单个时钟周期处理4x4矩阵元素
-
- MPI:多节点通信
- OMP:单 CPU 多核
- CUDA:深度学习,异构计算
-
RDMA相关问题。
RDMA (Remote Direct Memory Access) 是一种高性能网络通信技术,允许计算机在不经过操作系统内核的情况下,直接访问其他计算机的内存。这种技术能够显著提高数据传输速度,降低延迟和CPU负载,特别适用于高性能计算、大数据处理、云计算等场景。
没用过 -
平时如何进行kernel的优化,会用到哪些工具?
太泛了,略过... -
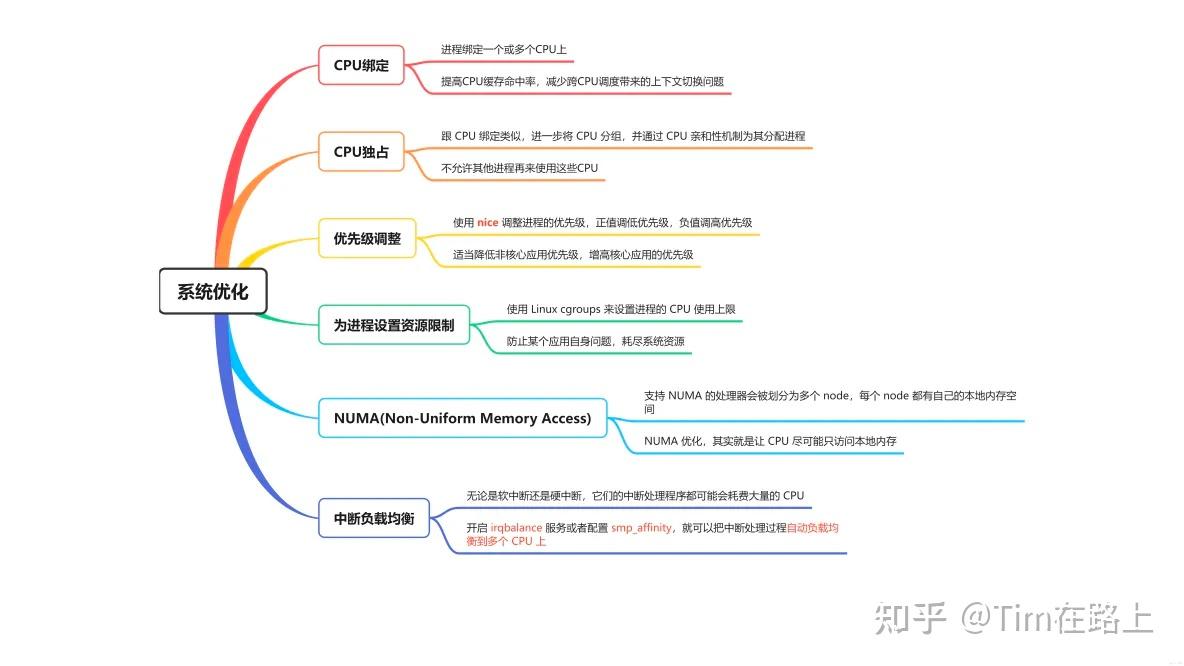
CPU上哪些并行优化方法?
- 编译层面,开O3,或者经验化搜索O2+最优编译flag
- 多线程/SIMD/异步操作(最后一个没用过)
- 缓存,
__builtin_prefetch - 系统层面
-
ARM相关的库有了解过吗?
-
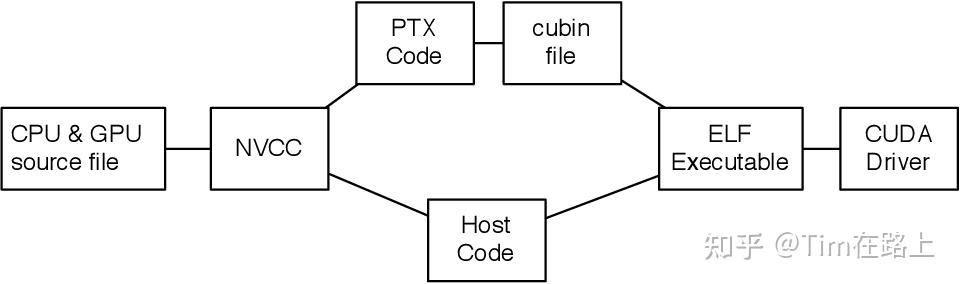
PTX有了解过吗?
类似于GPU的汇编语言,没看过
-
Roofline模型有什么用?如何确定最优的BLOCK_SIZE。
没看过... -
稀疏矩阵的存储格式有哪些?稀疏矩阵的应用场景?稀疏矩阵计算与稠密矩阵计算有何不同?
-
GPU资源调度有哪些方法?
-
稀疏矩阵的存储格式有哪些?稀疏矩阵的应用场景?稀疏矩阵计算与稠密矩阵计算有何不同?
-
如何计算CPU指令的吞吐量和时延?