挑出一些最常见的...准备一下,同步归档到CUDA.README和anki
国内大厂GPU CUDA高频面试问题汇总(含部分答案) - Tim在路上的文章 - 知乎
https://zhuanlan.zhihu.com/p/678602674
目录
- 基础概念
- 应用
- 常见kernel优化
CUDA 基础
-
CUDA 编程中的 SM 和 SP 是什么?
-
SP (Streaming Processor) 是最基本的处理单元,即计算核心 → thread
-
SM (Streaming Multiprocessor) 是由多个 SP 和其他资源组成的处理单元 → block
-
CUDA 线程的层次结构是怎样的?
- CUDA 的线程组织为3.5级层次结构:Thread, Warp, Block, Grid
- 层次结构
- 32thread=1warp,可以shuffle交换数据,调度的基本单位?
- 1024 thread(32warp)= 1 block,有shared memory
- 若干block = grid,一个kernel call/global memory的单位
-
什么是 Kernel 函数?如何定义和调用?
Kernel 函数是在 GPU 上并行执行的特殊函数,通过__global__修饰符定义,只能从主机代码调用。 -
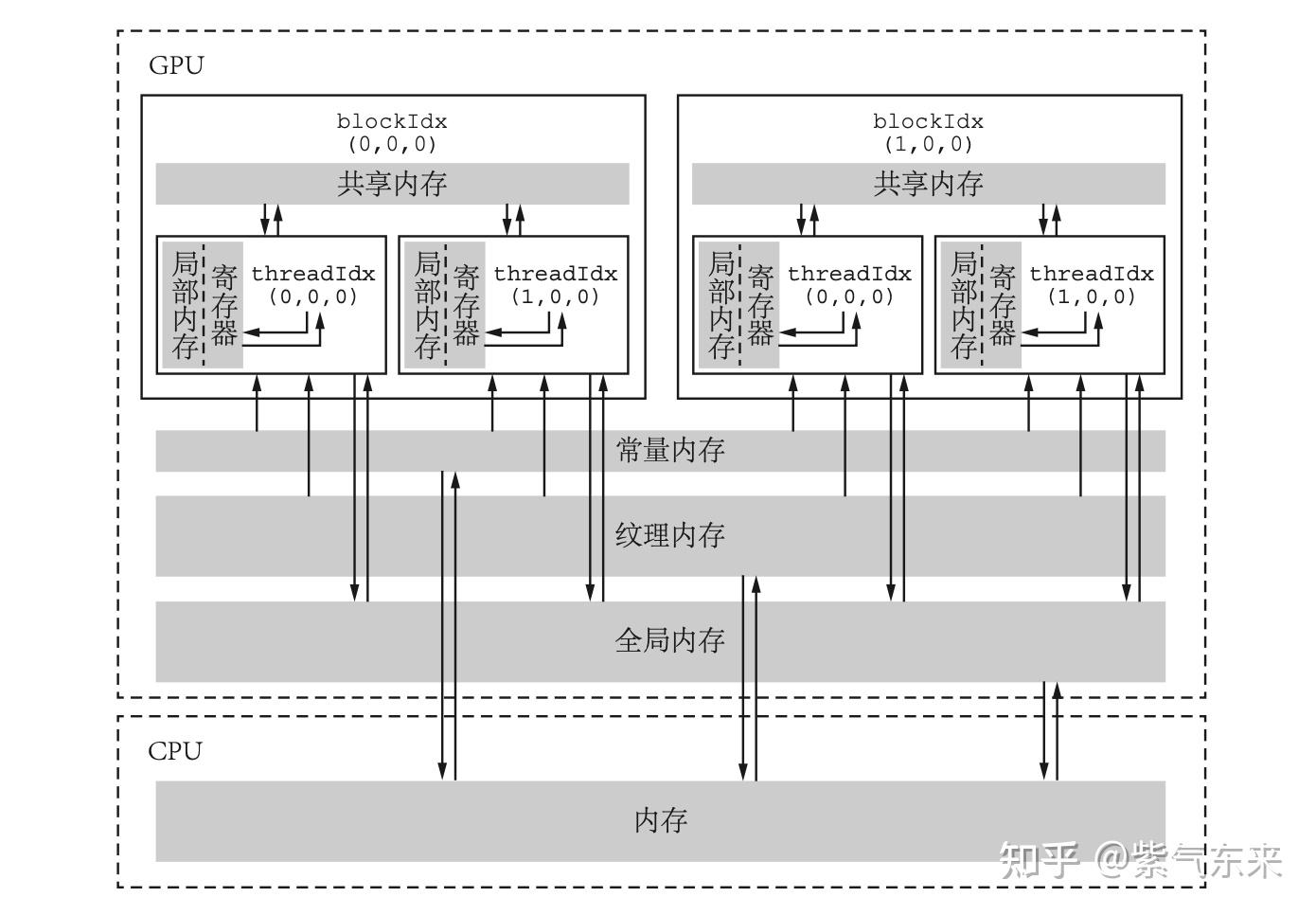
CUDA 内存模型有哪些? #TODO
CUDA 主要涉及全局内存 (Global Memory)、共享内存 (Shared Memory)、常量内存 (Constant Memory) 和寄存器 (Registers)。
一个比较好的解说
- 怎么理解GPU里的常量内存 #TODO
- 存储在片下存储的设备内存(aka全局内存)上,但是通过特殊的常量内存缓存进行缓存读取,常量内存为只读内存,只有64KB。由于有缓存,常量内存的访问速度比全局内存高。
- 使用常量内存的方法是在核函数外面用
__constant__定义变量,并用函数cudaMemcpyToSymbol将数据从主机端复制到设备的常量内存后供核函数使用。
-
什么是共享内存(Shared Memory)?它在 CUDA 中的作用是什么?
共享内存是在线程块中的多个线程之间共享的内存区域,用于加速多个线程之间的数据交换和通信。 -
CUDA 硬件线程束(Warp)是什么?
线程束是 GPU 硬件的执行单元,由一组 32 个线程组成,这些线程并行执行相同的指令。参见warp,这里说的更详细 -
CUDA 流 (stream) 概念的理解。
-
主机发出的在一个设备中执行的 CUDA 操作,包括主机-设备数据传输和 kernel 执行。
-
类比cpu里的process
-
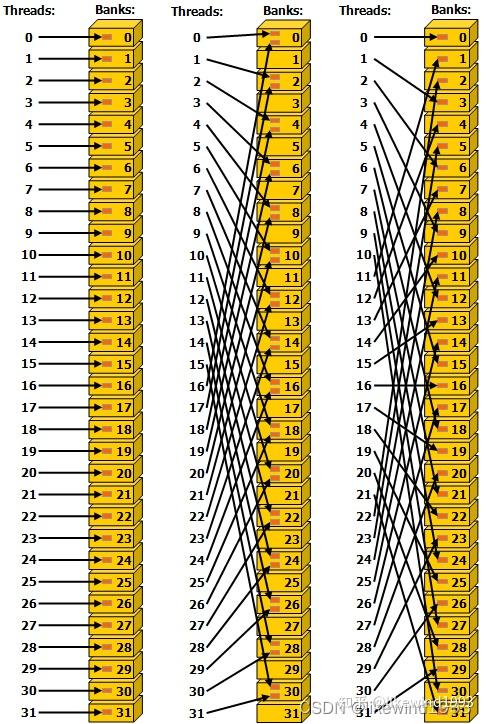
什么是GPU里的bank,动机是什么
-
对shared memory的一种划分,shared_memory 映射到大小相等的32个Bank上,Bank的数据读取带宽为32bit / cycle
-
不同的bank可以被同时访问,提高读写效率
-
bank是怎么划分的
-
bank i 占有 0+i,32+i,64+i...地址索引的shared memory
- bank conflict
- 同一个warp里的不同线程读同一个bank里的数据,会变成顺序读写
- 下图中间情况(为啥此时不触发broadcast)
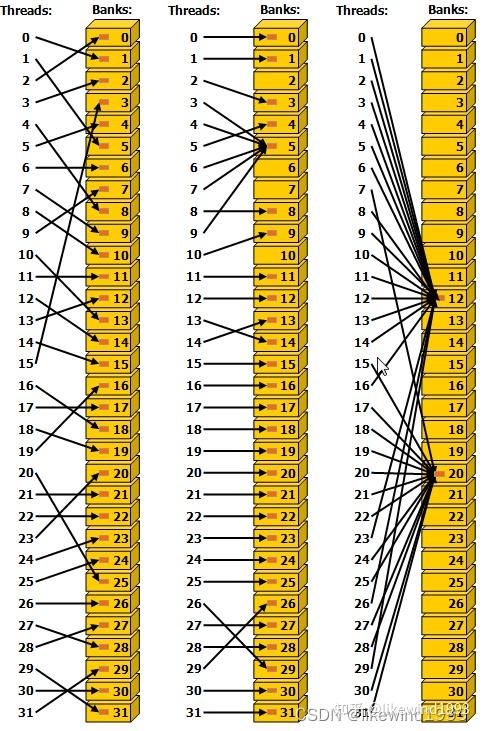
- 介绍一下能一定程度上避免bank conflict的 Broadcast机制
- 当一个warp中的所有线程/多个线程读写同一个地址时,会触发broadcast机制,此时不会退化成顺序读写
CUDA 优化
- CUDA 性能优化技巧有哪些?
- 判断bound,有计算 bound,访存 bound,io bound,各自的优化方法是:
- 计算bound:从算法和硬件利用两方面实打实提升效果,eg:矩阵乘,prefill截断llm推理
- 访存bound:减少/合并访存,利用共享内存,eg:vector add,spmm,decode阶段llm推理
- 访存bound -> 内存访问优化
- 合并内存访问,aka用 thread idx来索引访问内存位置,当warp中的线程访问连续内存块时(如thread 0访问addr0,thread 1访问addr1),GPU会合并为一次全局内存事务
- 使用共享内存,常量内存
- double buffer,读写分离
- general->执行配置优化
- general->指令级优化
- 避免分支,用mask代替if,保证warp之间不会阻塞
- 用内置函数,cuda math library之类
- IO →数据传输优化
- 使用
cudaMemcpyAsync重叠计算与传输 - 零拷贝内存(Zero-Copy Memory)
- 使用
- 怎么profile一个torch cuda程序
- profile程序
- torch profiler
- nsys
- 看汇编,一般来讲(至少在矩阵乘法里),计算指令占比越高越好
-
如何避免共享内存的 bank conflict?
-
padding:在声明共享内存时,人为增加每行的宽度(例如
__shared__ float arr[32][33]而非[32][32]),使得相邻线程访问不同bank。 -
调整访问模式:使用块状(blocked)访问模式,如
arr[threadIdx.y][threadIdx.x]替代arr[threadIdx.x][threadIdx.y],或者说让相邻的thread访问相邻的内存 -
自带广播优化:若所有线程读取同一地址(如
arr[0]),CUDA会将其优化为广播,不触发bank conflict。 -
使用
volatile关键字避免编译器优化导致意外的内存访问重排 -
CUDA 中不同内存类型的优化策略是什么?
- 全局内存:合并内存访问,使用 coalesced 访问。
- 共享内存:利用共享内存以减少全局内存访问,注意避免 bank conflict。
- 寄存器:有效利用寄存器以减少内存访问,但避免寄存器溢出。
- 常量和纹理内存:对于不变或重复访问的数据,使用常量和纹理内存以利用其缓存机制。
-
CUDA 流式多处理器(SM)是什么?它如何提高 GPU 性能?
CUDA 流式多处理器(SM)是一种硬件结构,用于执行 CUDA 核函数,多个 SM 可以并行执行不同的任务,从而提高 GPU 性能。 -
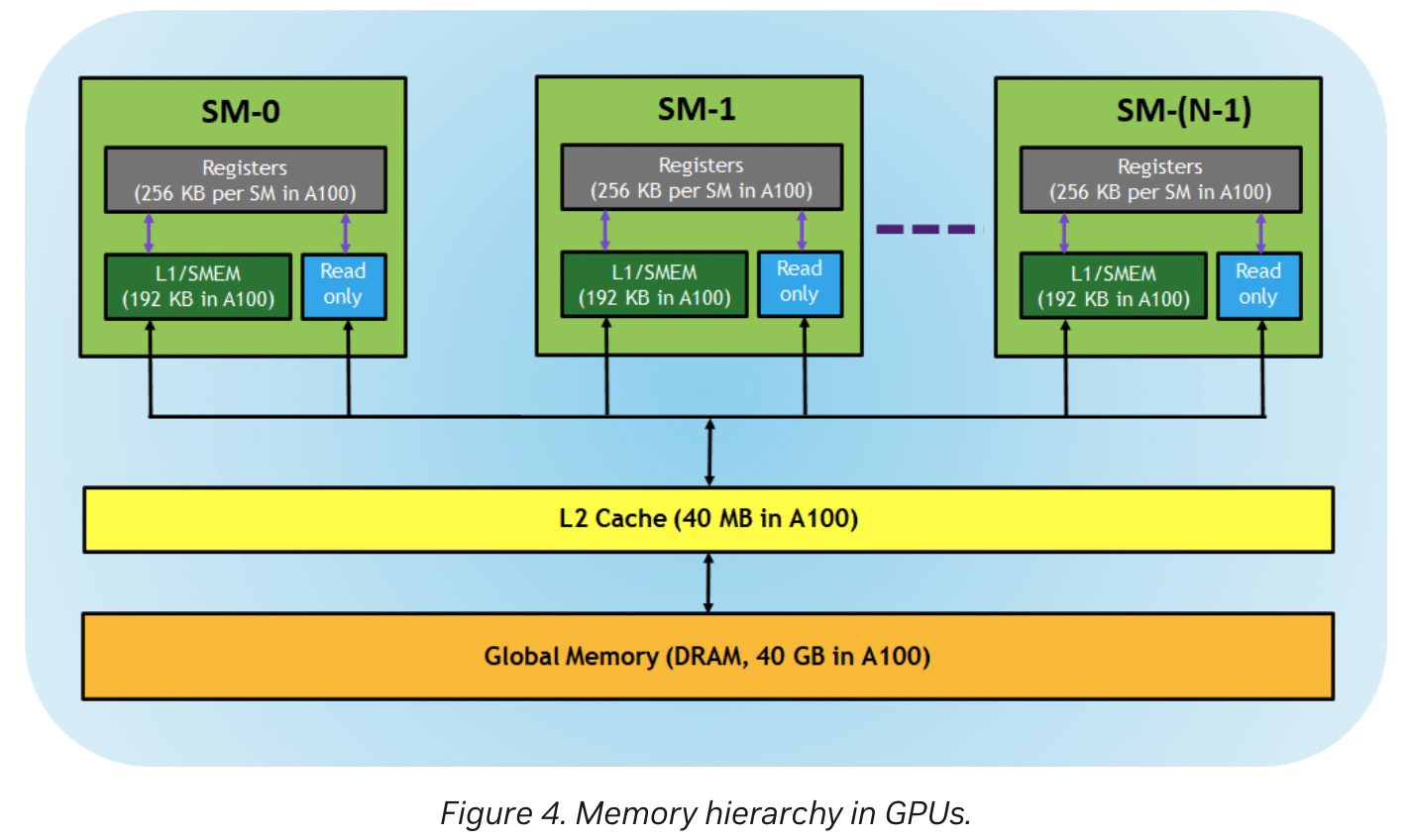
介绍GPU L1 缓存和L2缓存
- L1 cache是shared memory cache
- L2cache是global memory cache
CUDA 应用
- GEMM优化
- 访存:
- 把数据预加载到shared memory和register,加载的同时转置
- float4加载数据
- double buffer读写分离
- register重排以避免bank冲突 暂时没懂
- 计算:
- FFMA指令(需要编译符号吗,还是很聪明地就会这样)
- sudo code in sgemm v3
- Load A/B into shared memory
- Load A/B into register
- main Loop,for tile in tiles
- load next tile into shared memory,switch read/write pointer
- current tile loop,for 4 in THREAD_SIZE=8
- load next data into register
- compute current tile
- 处理最后一块,即内层循环中
j=BLOCK_SIZE_K-1时对应的一组,但内层循环只到BLOCK_SIZE_K-2,所以这一步在循环外
- accum结果写回
- 资源划分
- 符号:A(M,K) x B(K,N) ⇒ C(M,N),似乎是某个牢库的标准,以后我的符号系统也统统如此
- 所有划分都开双缓冲,不再多次重复
- global memory划分到shared memory小block,MN级别的分块 128,K级别的分块8,长行方便内存读取
- shared memory到register的小block, 2x8,尺寸为8
- 全部用float4,aka 4x32=128bits的数据加载
- SpMM,esp在做的项目