Break the Sequential Dependency of LLM Inference Using Lookahead Decoding
我们基于一个关键观察:自回归解码可以等效地表述为通过定点雅可比迭代方法(第2节)求解非线性系统,我们将其称为雅可比解码。每个雅可比解码步骤可以在不同位置并行生成多个令牌。尽管这些标记可能出现在不正确的位置,但我们可以利用这种并行生成方法,让LLM在一个步骤中并行生成多个不相交的n 元语法。这些 n-gram 可能会集成到生成序列的未来部分中,等待基本模型的验证以维持输出分布。
看不懂,先往后看
支持前向解码的关键观察是,尽管一步解码多个下一个标记是不可行的,但LLM确实可以并行生成多个不相交的n 元语法。这些 n-gram 可能适合生成序列的未来部分
background
Jacobi Decoding.
假设我们有自回归解码,默认贪婪采样,x0 prompt
我们定义一个函数
因为采用贪婪解码,所以这里的数值都=0
- 我们可以使用雅可比迭代,从随机的初始条件开始生成正确的数值。
- 任意两个token 2-gram
怎么理解
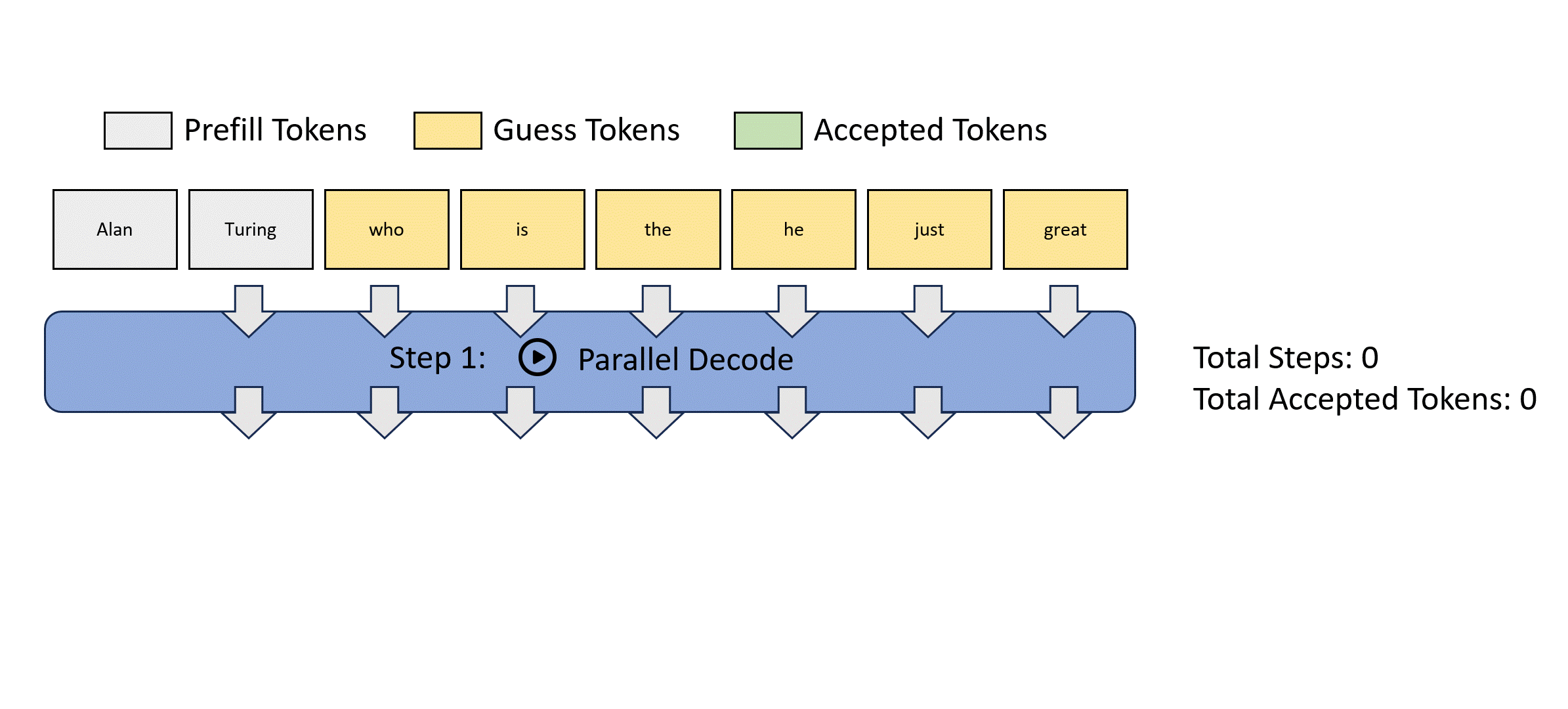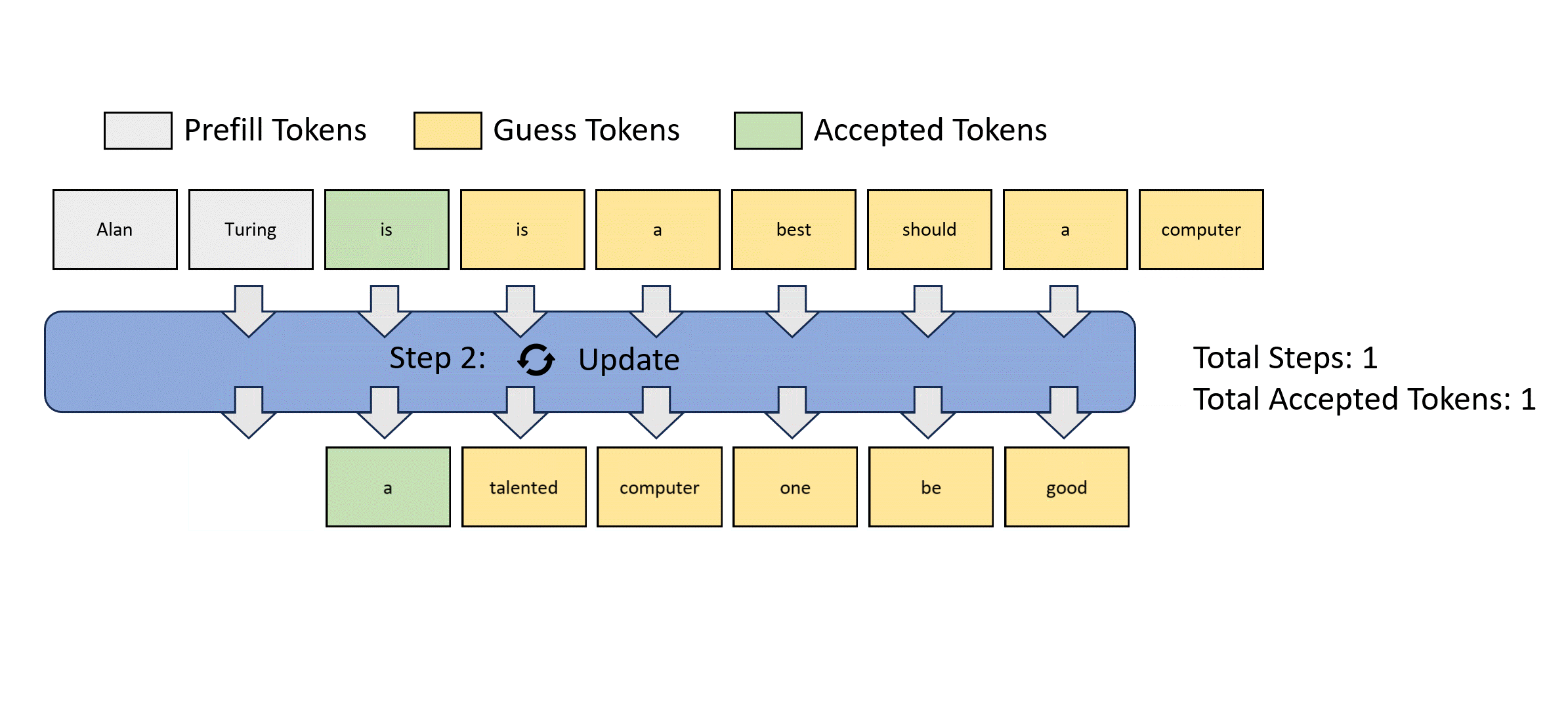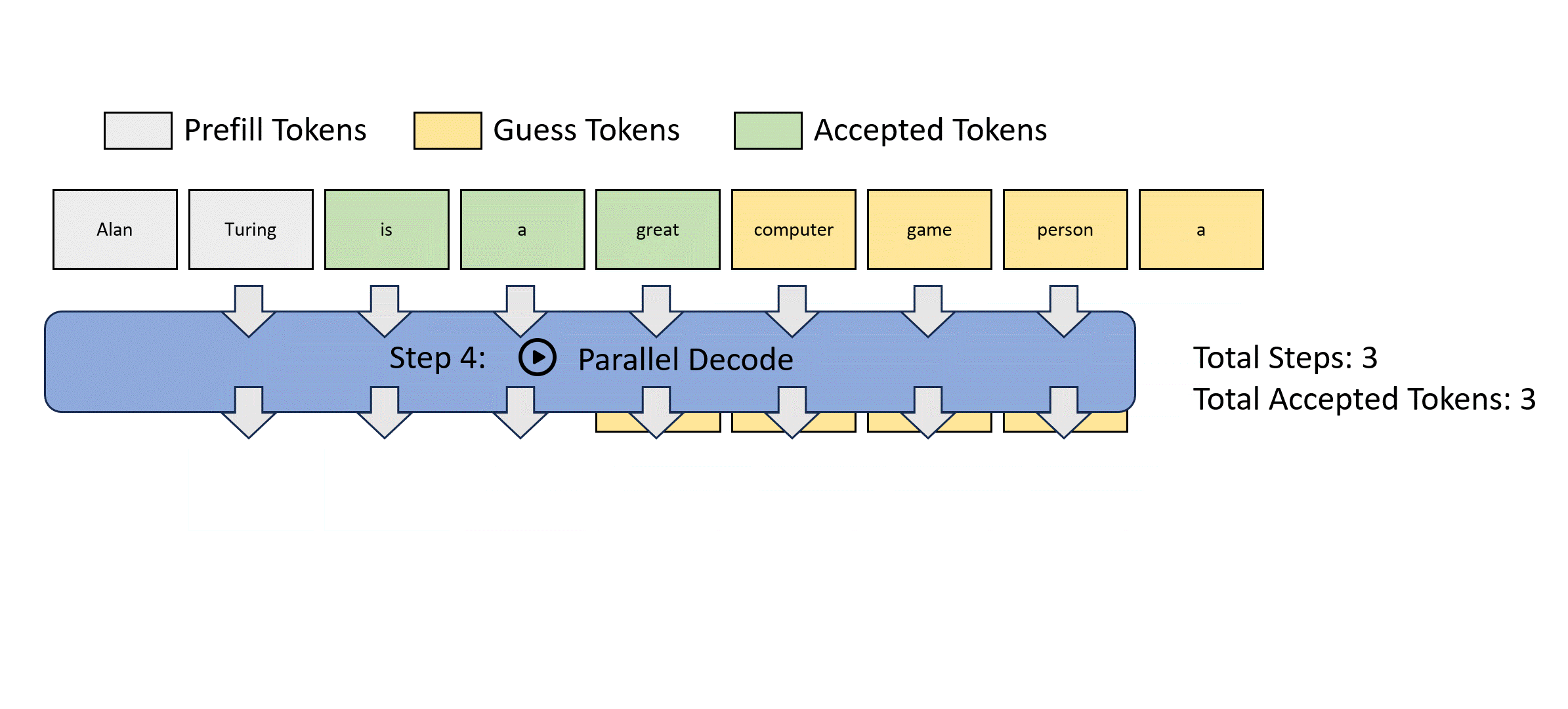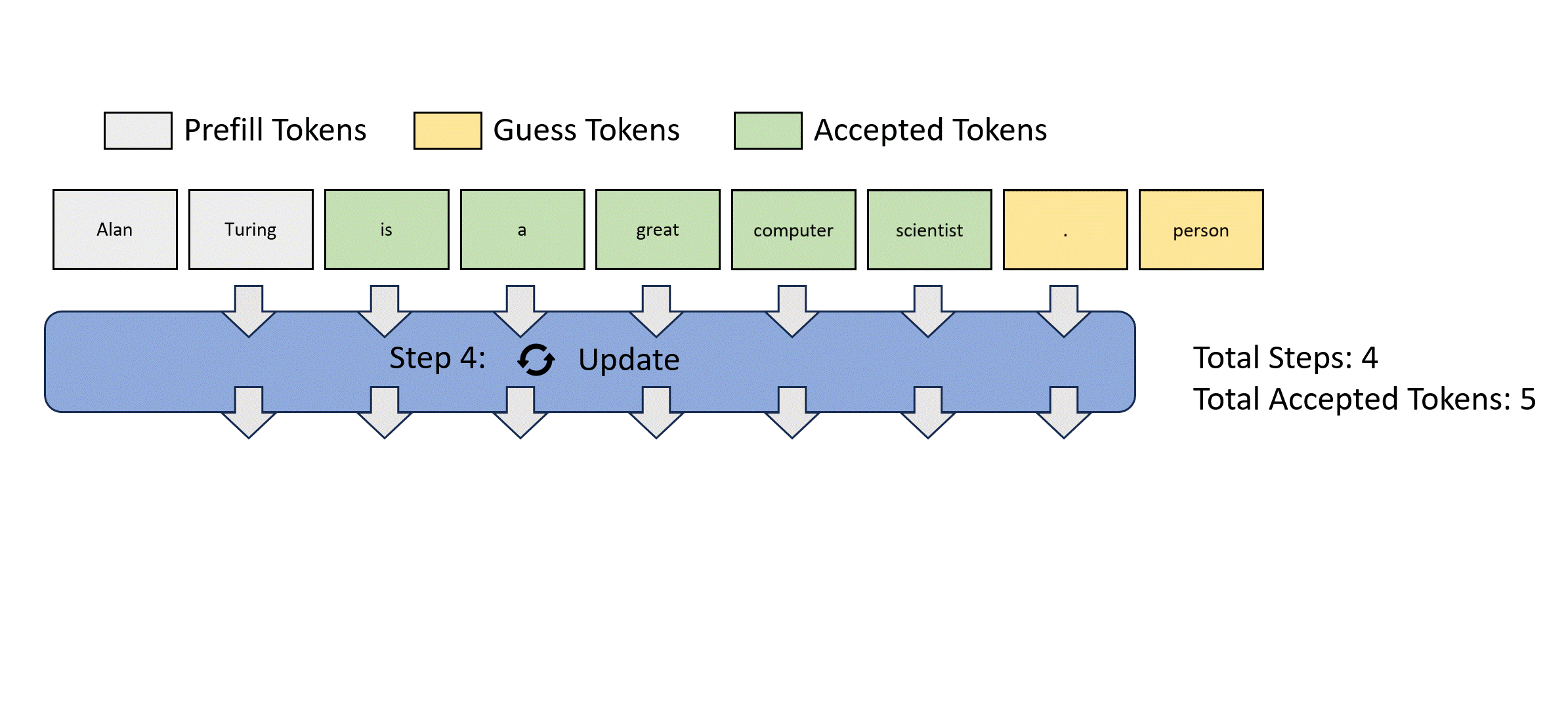
- 最初的猜测串从哪里来?
- 都是大模型可以并行解码一堆东西,这就是类似投机解码并行验证的机制,只是论文里说的玄乎
然它可以在许多步骤中解码多个令牌,但在序列中精确定位这些令牌常常会出错。即使标记被正确预测,它们也经常在后续迭代中被替换。因此,很少有迭代能够成功实现多个令牌的同时解码和正确定位。
可以预测出正确的token,但位置错误,怎么样让这种不浪费?
一遍验证,一边存若干n-gram序列
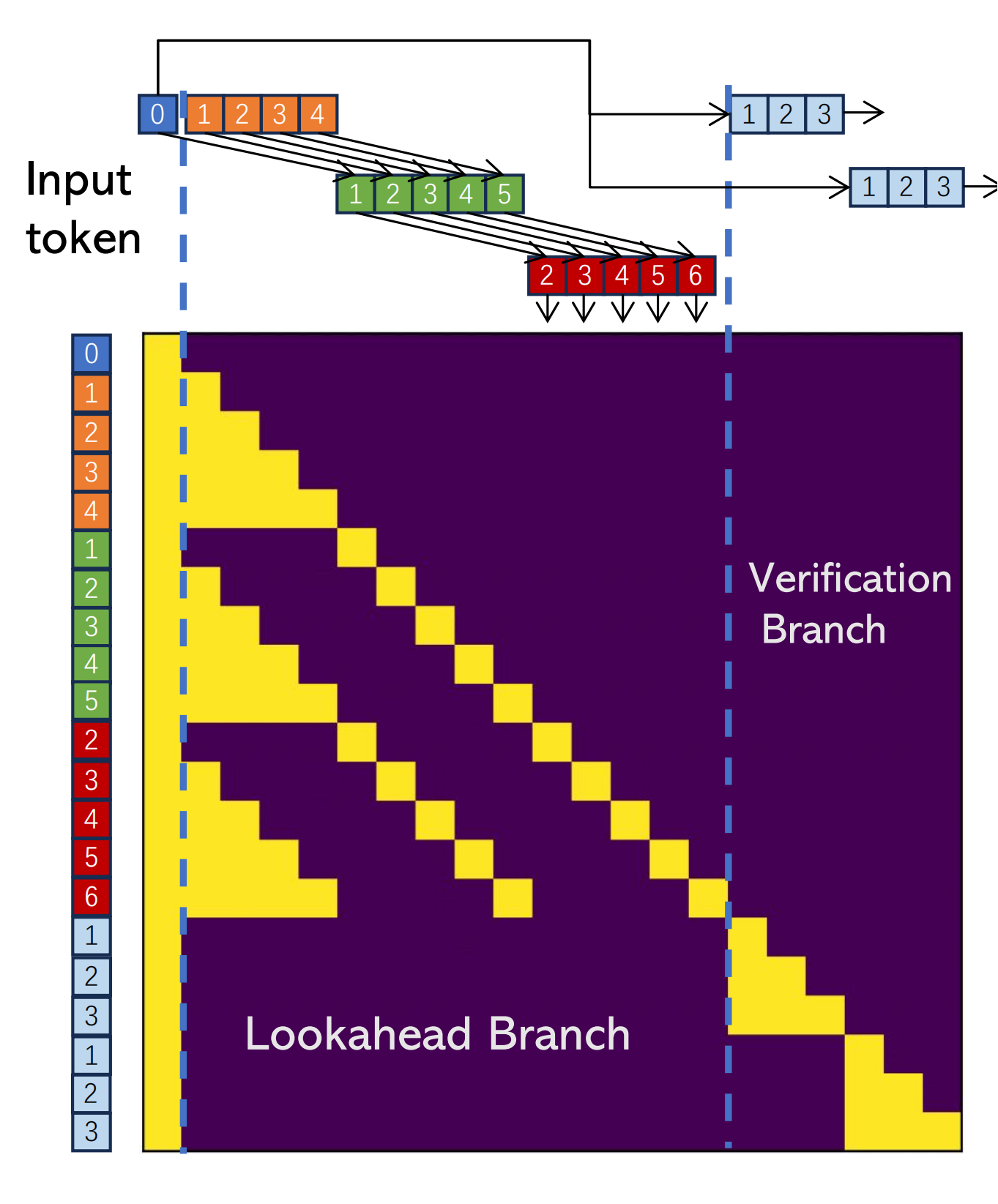
每个先行解码步骤被分为两个并行分支:lookahead branch和verification branch.。lookahead branch维护一个固定大小的 2D 窗口,以根据雅可比迭代轨迹生成 n 元语法。同时,验证分支选择并验证有前途的 n-gram 候选者
lookahead branch
Lookahead 分支旨在生成新的 N-gram
参数
(1) W defines the lookahead size into future token positions to conduct parallel decoding; 一次推多少个未来token
(2) N defines the lookback steps into the past Jacobi trajectory to retrieve n-grams 用多长 n-gram pool
n是不是=2的时候最直觉,否则n>2 验证
这图真看不懂
W=5,所以一步验证5个
N=3 用3-gram池检索
然后这里在一步注意力操作中实现...?
好像有点明白,感觉那个gif最好,这attention mask属于技术细节?
下面是paper的note,上面是博客的解说
Lookahead Decoding

W=5, N=3, G=2
对于每个解码步骤,我们执行以下操作。
(1) 在lookahead分支的每个位置生成一个token;
(2) 通过验证分支验证并接受 3-gram(从 3-gram 池中搜索);
(3) 从前瞻分支轨迹中收集并缓存池中新生成的 3-gram。
(4)更新前瞻分支以维持固定的窗口大小。
此外, Lookahead Decoding引入了n -gram 池来缓存这些n -沿轨迹生成的东西
lookahead branch
两个参数
(1) W defines the lookahead size into future token positions to conduct parallel decoding; 一次推多少个未来token
(2) N defines the lookback steps into the past Jacobi trajectory to retrieve n-grams 用多长 n-gram pool
具体说明

蓝色0:当前输入token
橙色,红色,蓝色 ❓
每个标记上的数字显示其与当前输入的相对位置(即标记为 0 的蓝色标记)
t-x是什么意思...