自回归解码使得大型语言模型 ( LLMs ) 的推理非常耗时。在本文中,我们重新考虑推测性抽样并得出两个关键观察结果。
- 首先,特征(第二层到顶层)级别的自回归比令牌级别更直接。
- 其次,特征(第二层到顶层)级别的自回归固有的不确定性限制了其性能。
基于这些见解,我们引入了 EAGLE(提高语言模型效率的外推算法),这是一个简单但高效的推测采样框架。通过合并一个时间步长的令牌序列,EAGLE 有效地解决了不确定性,以最小的开销实现精确的第二层到顶层特征预测。我们对 EAGLE 进行了全面评估,包括 Vicuna 和 LLaMA2-Chat 系列的所有模型、MoE 模型 Mixtral 8x7B Instruct 以及对话、代码生成、数学推理和指令跟踪等任务。对于 LLaMA2-Chat 70B,EAGLE 实现了2.7x-3.5x的延迟加速比,吞吐量翻倍,同时保持了生成文本的分布。
Introduction
瓶颈和已有工作
- 自回归... 投机解码...
- 怎么找草稿模型。
- 最小的7B 变体很棘手
- TinyLLaMA ,但由于 LLaMA2-Chat 和 TinyLLaMA-Chat 之间的指令模板不一致,因此对于指令调整模型来说是不可行的。
- 增强推测性抽样加速的关键在于减少时间开销,提高原LLM的稿件接受率
我们的方法
基于两个观察
- 特征级别的自回归比标记级别的自回归更简单, autoregression at the feature level is simpler than at the token level
- “特征”指的是原始LLM的第二层特征second-to-top-layer features of the original LLM,位于LM头之前
- 在特征级别进行自回归处理,然后使用原始LLM的 LM 头导出token,比直接自回归预测标记产生更好的结果。
- 【意思是换了个地方预测下一个token,在哪里不知道,后面再看】
- 其次,采样过程中固有的不确定性极大地限制了预测下一个特征的性能
- 就是LLM输出的tensor是概率,然后通过采样,可能产生不同的下一个token,然后严重限制对next n token预测的性能
- 为了解决这一问题,EAGLE 将提前一个时间步的token序列(包括采样结果)输入到草稿模型中。
- 以下图为例,predicting
based on and
- 以下图为例,predicting

效果
- 效果特别好...可以和其他优化方法并行
- 好训练,EAGLE 在 7B、13B 和 33B 模型上的训练甚至可以在 RTX 3090 节点上进行 1-2 天的训练
- 通用
Preliminaries
- “特征”通常表示LLM的第二层特征,即 LM 头之前的隐藏状态
- 补充: LM头是什么
“LM 头”通常指的是 语言模型头(Language Model Head)。这是模型的最后一层,负责生成最终的输出,比如预测下一个单词或生成文本。
!EAGLE Speculative Sampling Requires Rethinking Feature Uncertainty 2024-11-29.excalidraw
EAGLE
Drafting phase
overview
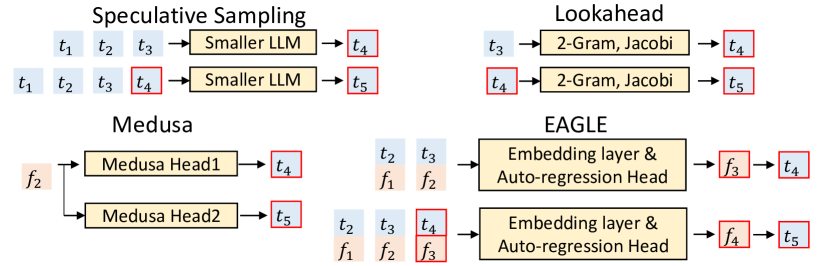
不同的方法👀
- Speculative sampling / lookahead 用token推测token
- Medusa 用来自同一个LLM的feature
,独立预测 和 - EAGLE 预测feature
,使用token , ,feature ,
图片说明
- token t 蓝色
- featrue f 橙色
- The red border indicates the predictions of the draft model.
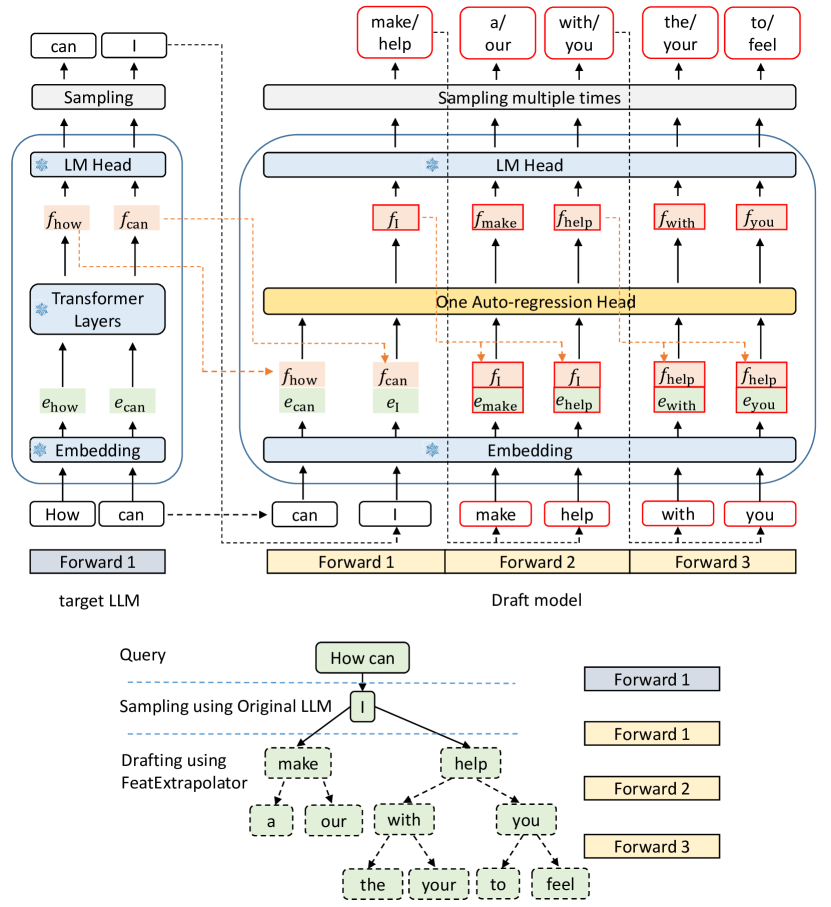
模型架构
- EAGLE的草稿模型包括三个模块:Embedding层、LM Head和Autoregression Head
- Embedding 层和 LM Head 使用目标LLM的参数,不需要额外的训练
- Autoregression Head的数据流:
- 将形状为 (bs, seq_len, hide_dim) 的feature序列和形状为 (bs, seq_len) 的高级token序列作为输入
- 将token序列转换为形状为 (bs, seq_len, hide_dim) 的标记嵌入序列,然后连接成
(bs, seq_len, 2×hidden_dim)的序列,通过全连接层变回(bs, seq_len, hide_dim) - decoder laybers
- 使用tree attention创建tree draft
原图
Training of the draft models
训练目标
- 这里训练的是上图
One Auto-regression Head - 训练目的:
- 预测下一个feature → 采取Smooth L1 loss
- 预测token → 采取分类损失
\hat{p_{i+2}}=\text{Softmax}(\text{LM_Head}(\hat{f_{i+1}}))\ \
L_{cls}=\text{Cross_Entrophy}(p_{i+2},\hat{p_{i+2}})
\end{array}
$$
- 损失整合,以「通常,分类损失在数值上比回归损失大一个数量级」的经验规则确定
训练数据
- 用已有数据集训练
- 理想状态:使用来自目标LLM自回归生成的文本进行训练,但成本高
- 但 EAGLE 对训练数据表现出较低的敏感性
- ⇒ 使用固定数据集,减小开销
- drafting phase,自回归,特征的不准确可能会导致错误累积
- ⇒ 训练的时候增加均匀分布中采样的随机噪声
- ⇒ 训练的时候增加均匀分布中采样的随机噪声
Verification phase
- 利用树注意力,目标LLM通过一次前向传递计算树结构草案中每个标记的概率。
- 在草稿树的每个节点,我们递归地应用推测采样算法来采样或调整分布
- 与 SpecInfer 一致
- 我们记录已接受的token及其feature,以便在下一个起草阶段使用
Experiments
Models and tasks
- models: Vicuna models (7B, 13B, 33B), LLaMA2-chat models (7B, 13B, 70B), and Mixtral 8x7B Instruct
- tasks: MT-bench, HumanEval, GSM8K
- 以及测试了不同的温度T=0, T=1
- 指标:
- Walltime speedup ratio,相比普通投机解码的加速
- Average acceptance length
- Acceptance rate
- 衡量起草的准确性
- 用没有树注意力的链草案衡量
- 自回归特征处理会传播错误,因此我们将接受率测量为
,考虑到n草稿模型预测的特征可能不准确 表示当输入包含一个不精确特征时的接受率
和其他方法比较的加速比
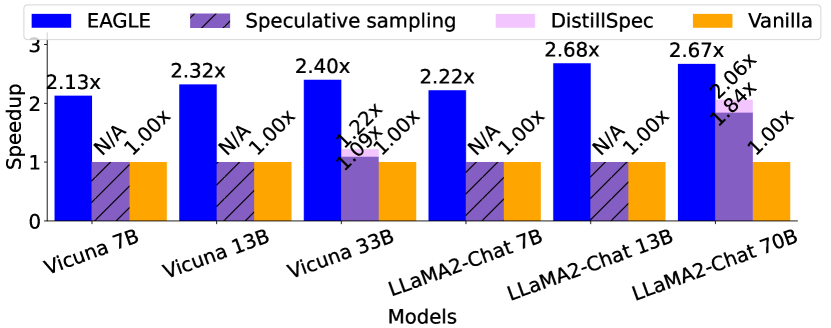
Lookahead仅限于贪婪解码,Medusa的非贪婪生成并不能保证无损性能。因此,EAGLE 不与这些方法进行比较
不同模型/数据集上的表现
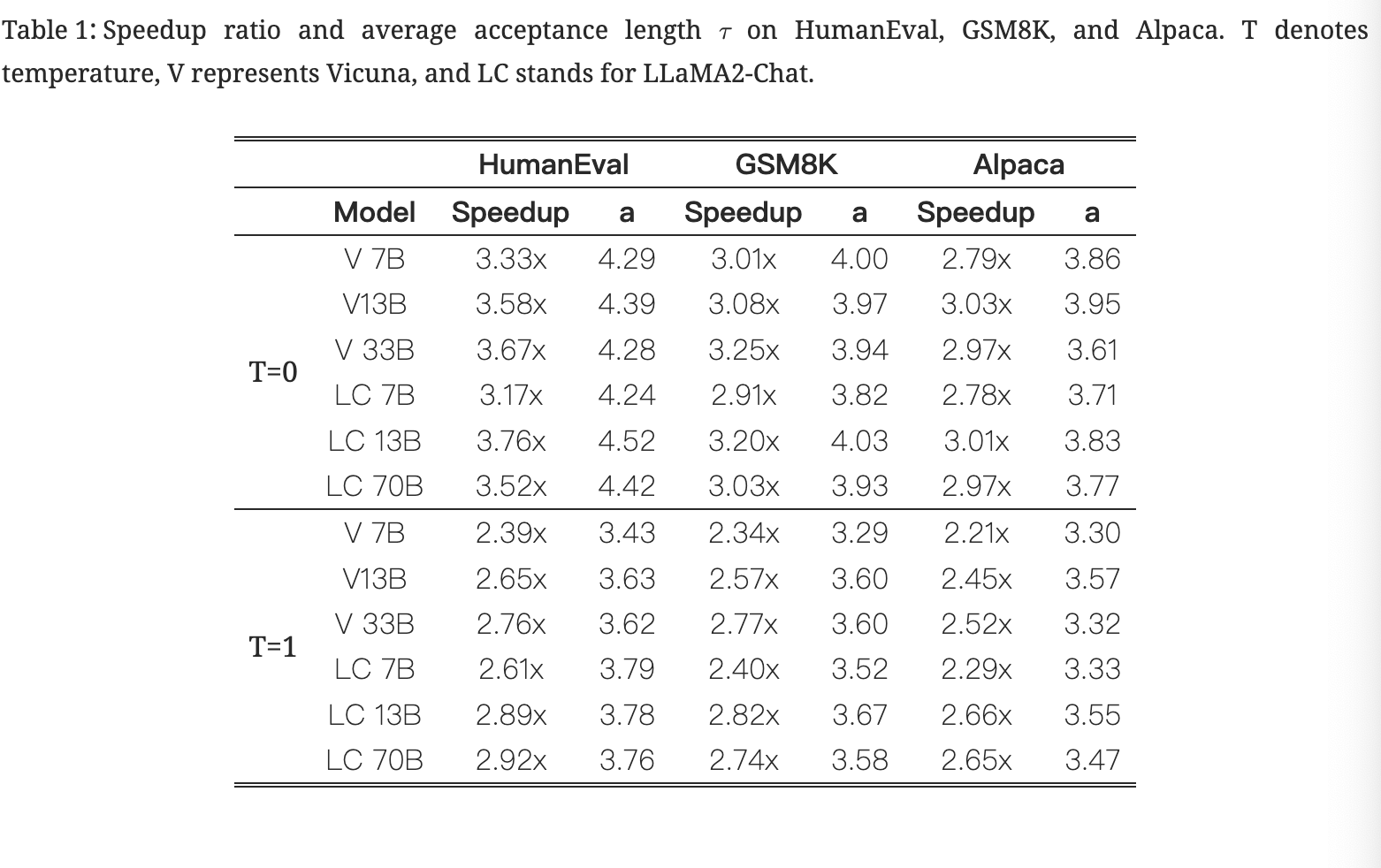
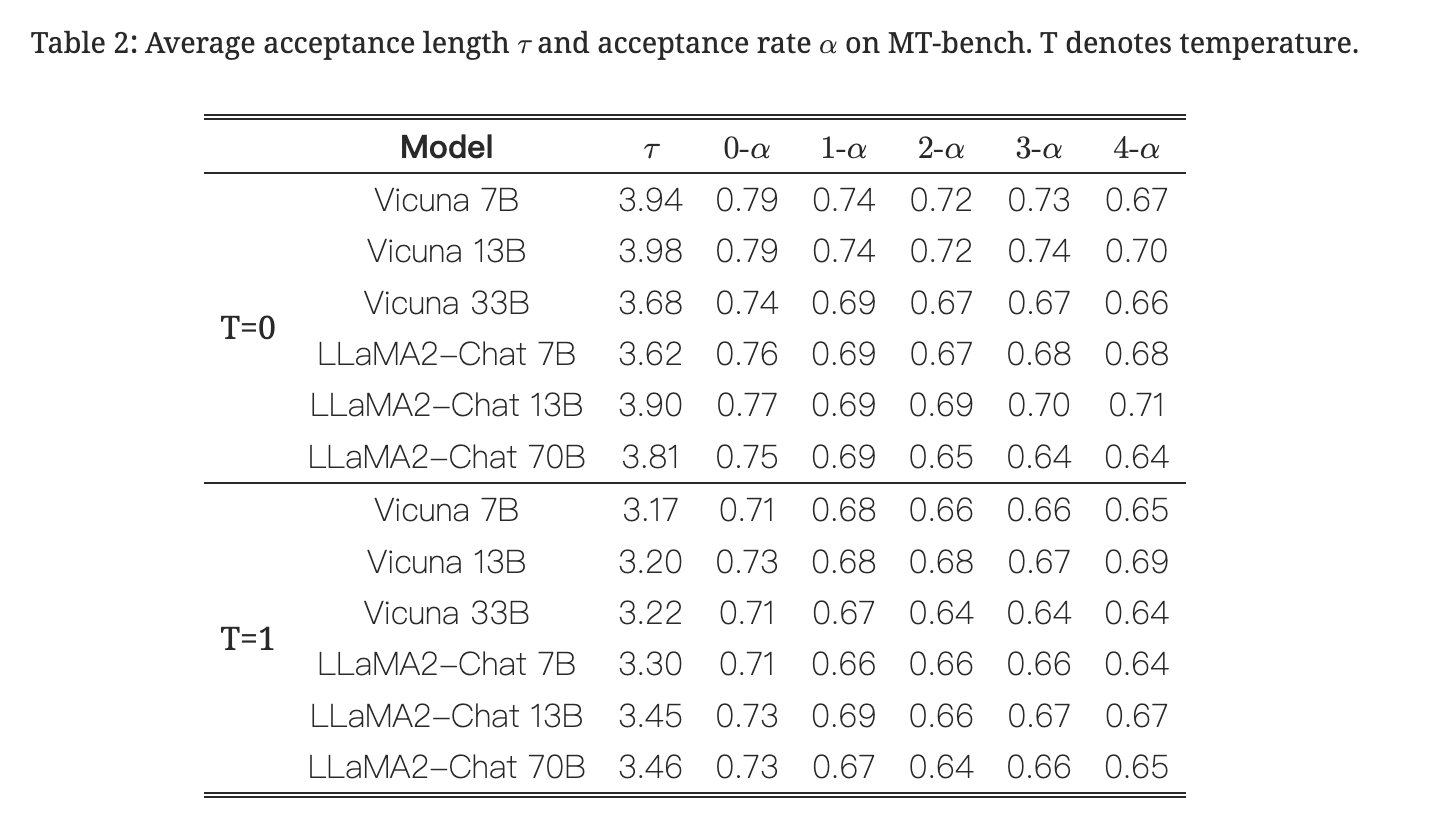

Train
- EAGLE 在 ShareGPT 数据集上进行训练,使用 68,000 次对话迭代,学习率设置为 3e-5
- 采用了具有 beta 值的 AdamW 优化器,
- 0.5 的梯度裁剪
- 对梯度进行缩放或者设置上下限,防止梯度爆炸
- 7B、13B、33B、70B模型对应的EAGLE可训练参数分别为0.24B、0.37B、0.56B、0.99B
- MoE 模型 Mixtral 8x7B 的 EAGLE 可训练参数为 0.28B
Case study: EAGLE + gpt-fast
- EAGLE 与其他加速技术兼容
- gpt-fast,采用量化和编译来加速

Ablation study
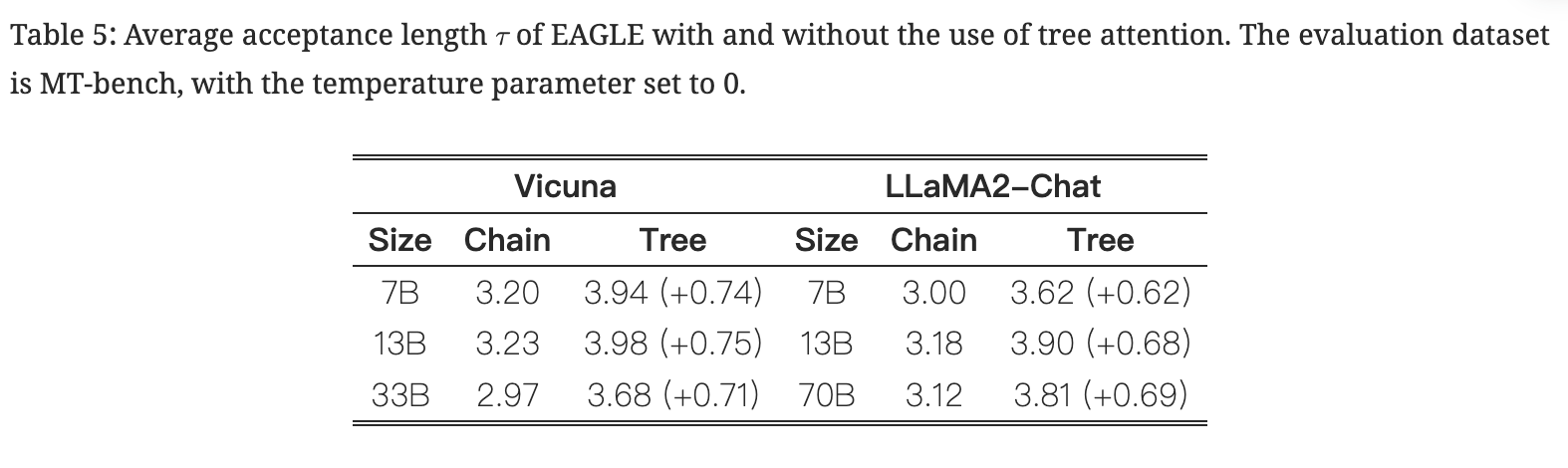
tree attention
- 两种投机解码方法
- EAGLE 与 SpecInfer 和 Medusa 类似,采用树注意力机制,草稿的生成和验证都是树结构的。
- 相比之下,像speculative sampling这样的方法不使用tree attention,从而导致链式结构的草稿生成和验证
- tree drafting 对 EAGLE的作用: 平均接受长度大约增加0.6-0.8,加速比大约增加0.3-0.5
- 与chain drafting相比,tree drafting不会增加模型(目标LLM和草稿模型)的forward passes数量,但它们确实增加了每个forward passes处理的token数量
- 因此,加速比的改善不如平均接受长度的增加明显
- EAGLE 对 chain drafting也很有帮助: 即使不使用树草图和验证,EAGLE 也表现出显着的加速效果,大约在 2.3x-2.7x 范围内
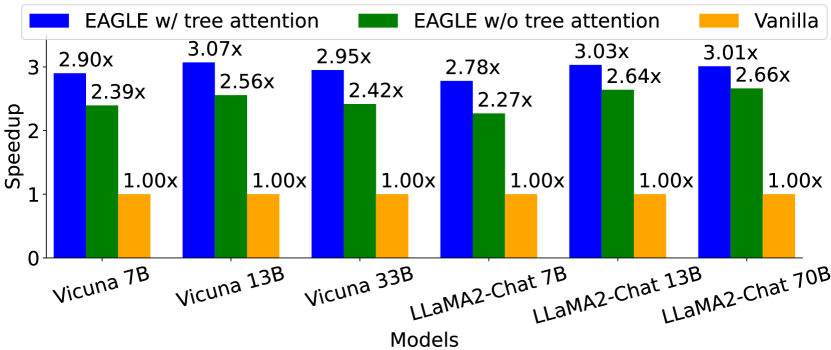
Figure 7:Speedup ratios of EAGLE with and without the use of tree attention. The evaluation dataset is MT-bench, with the temperature parameter set to 0.
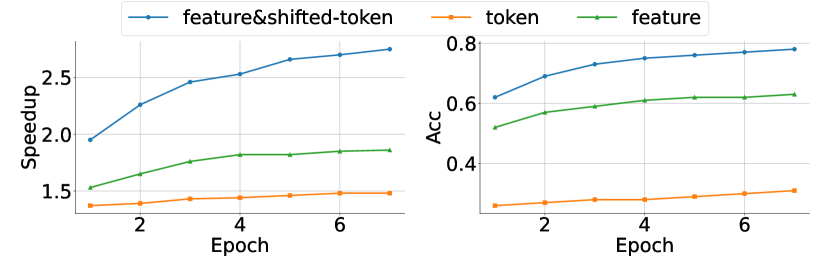
Inputs of draft models
- 与其他基于推测抽样的方法相比,EAGLE 的关键创新在于它利用了目标LLM计算的特征,并将抽样结果纳入草稿模型的输入以解决随机性问题。
- 我们对 Vicuna 7B 进行了消融研究,评估了具有不同输入的草案模型:
- 我们测试了四种类型的输入:feature&shifted-token (EAGLE)、feature&unshifted-token、token 和 feature。 feature&shifted-token (EAGLE) 和 feature&unshifted-token 都集成了不同级别的语义信息。
- 区别在于特征和转移令牌(EAGLE)输入提前一个时间步长的令牌,使其能够有效地解决随机性。
- 除了使用 FC 层来降低特征和令牌输入的维度之外,草稿模型的结构保持完全一致。
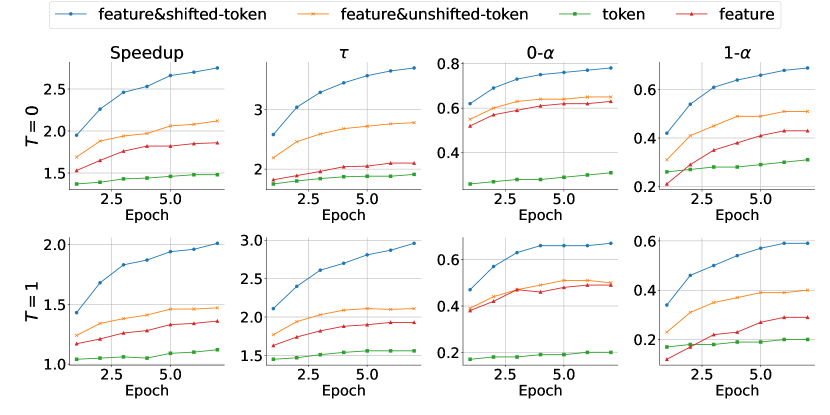
The target LLM is Vicuna 7B, and the test dataset is MT-bench.
观察结果:
- 当草稿模型的参数数量有限时,利用feature会产生比token稍好的结果
- 合并特征和令牌会适度提高性能
- 主要是因为离散、无错误的令牌减轻了特征错误累积,证据时
在 feature&unshifted-token 和 feature-only一样 明显提升
- 主要是因为离散、无错误的令牌减轻了特征错误累积,证据时
- 解决sampling过程中固有的随机性会带来最显着的改进
- 与 feature&unshifted-token 相比,feature&shifted-token 方案不会增加复杂性
- 但通过简单地将 token 推进一个时间步长,显着增强了草稿模型的能力,允许草稿模型考虑采样的随机性
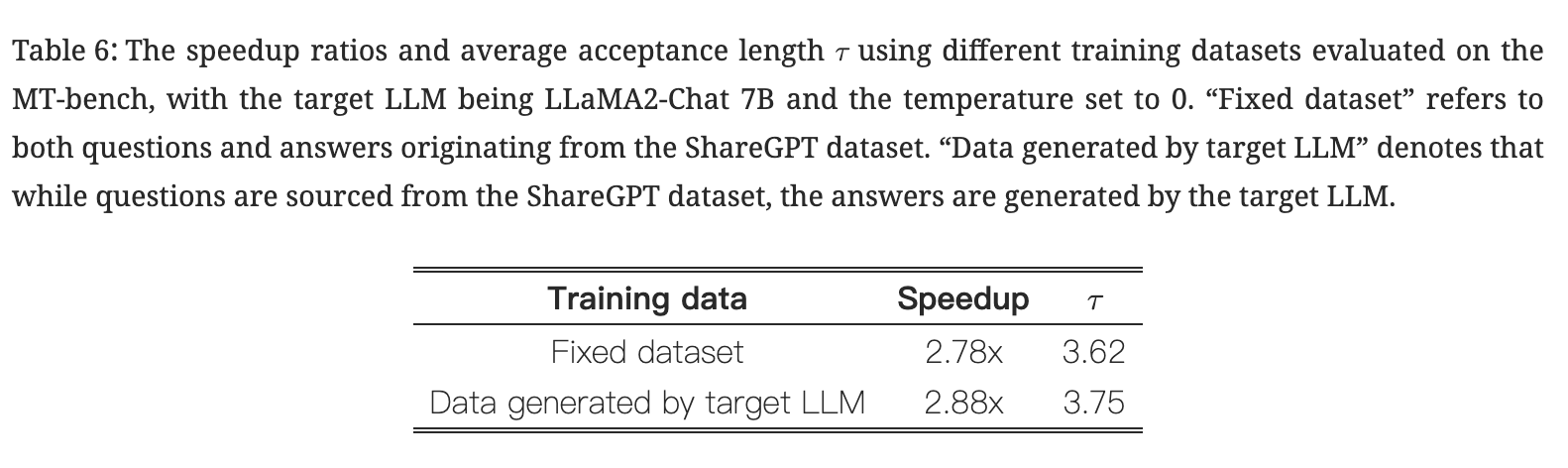
Training data
- EAGLE 使用固定数据集进行训练
- 来自目标LLM的数据略微提高了性能
- 表明 EAGLE 对训练数据的敏感性较低,并证明了固定数据集方法降低成本的合理性。
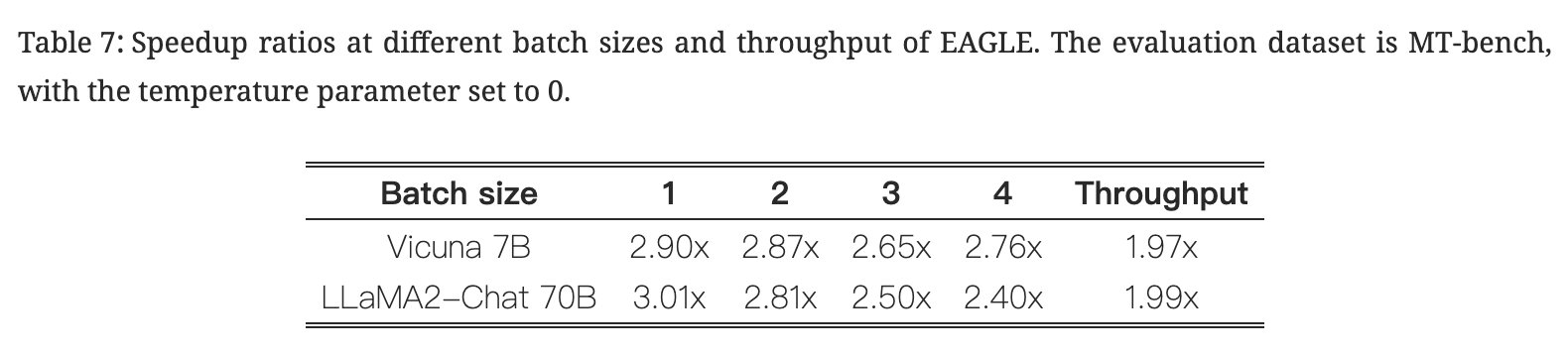
Batch size and throughput
- NOTE: Batch size是目标LLM的参数
- Batch size对推理速度影响
- 随着批量大小的增加,GPU的可用计算能力会减少,导致加速效果降低 ⇒ EAGLE的加速比随着batch size的增加而减小
- 当使用 Vicuna 7B 作为目标LLM时,bs=4 时的加速比高于 bs=3 时的加速比。
- 因为目标LLM验证更快,所以bs=4 速度大于bs=3
- 相比之下,在目标LLM每次前向传递处理一个令牌的普通自回归解码中,bs=3 和 bs=4 时的速度几乎相同。
- Throughput
- 与普通自回归解码相比,EAGLE 需要稍多的 CUDA 内存
- 目标LLM是 Vicuna 7B,在具有 24G CUDA 内存的单个 RTX 3090 的内存约束下运行,普通自回归解码和 EAGLE 的最大batch size分别为 8 和 7
- 目标LLM是LLaMA2-Chat 70B 受 4 个 A100 (40G) GPU 总计 160G CUDA 内存的限制,普通自回归解码和 EAGLE 的最大 bs 分别为 5 和 4。
- 所有评估均以 FP16 精度进行,计算了不同bs的吞吐量并选择了最大值
- 普通自回归解码和 EAGLE 都在各自的最大 bs 下实现了最大吞吐量
- 与普通自回归解码相比,EAGLE 需要稍多的 CUDA 内存