感觉看blog很困惑,需要看严肃的paper才好
#friend/wdl 讨论的时候说,先看数学公式和推导,再看「儿童画」比较好,如果一上来就看儿童画会困惑,这是一个新的observation,套用到这个语境里,我们学习的顺序是
- 基本的科普,比喻,儿童画,有一个大的概念,比如「LLM就是根据历史记录预测下一个词」,然后到这里就不要继续看科普了...
- 严肃论文/公式/官方实现,了解基础,熟悉备查,如自注意力公式,transformer代码
- 基础模型延伸出来的论文,看contribution和method里的画,如最新论文
之前琢磨出了1/3,但懒得2,导致经常在肤浅的问题里打转,这不好,要改变
所以看这篇:[1901.00596] A Comprehensive Survey on Graph Neural Networks,有点老,但是应该能补齐基础概念
Background
受图卷积启发,ConvGNNs are divided into two main streams:
- the spectral-based approaches
- the spatial-based approaches
Graph neural networks vs. network embedding,两个相反的方法,一个手动构造图,一个通过embedding之间的相似度来表示关系
现在看来,后者比较popular,可以参考这篇回答,说的是推荐系统,但或许可以推广到大部分dl领域
Graph neural networks vs. graph kernel methods,略,老ml时代的法子
Categorization and Frameworks
- Recurrent Graph Neural Networks (RecGNNs):pioneer works,用RNN,assume a node in a graph constantly exchanges information/message with its neighbors until a stable equilibrium is reached
- 类似pagerank?
- Convolutional Graph Neural Networks (ConvGNNs):继承上面的,generate a node v’s representation by aggregating its own features
and neighbors’ features - Spectral methods
- Spatial methods
- Graph Autoencoders (GAEs):encode nodes/graphs into a latent vector space and reconstruct graph data from the encoded information.
但为啥要「根据编码信息重建图数据」?- Network Embedding
- Graph Generation
- Spatial-temporal Graph Neural Network:for 时空图这类特殊格式
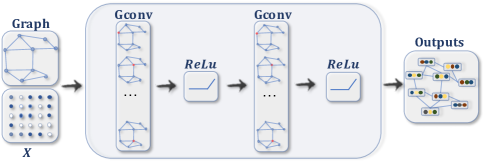
ConvGNN with multilayer⬇️
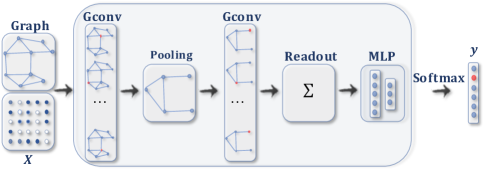
ConvGNN with pooling⬇️
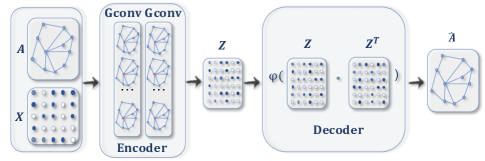
A GAE for network embedding⬇️
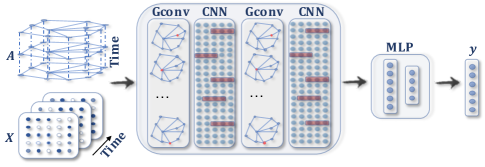
A STGNN for spatial-temporal graph forecasting ⬇️
任务
- Node-level
- node regression
- node classification
- Edge-level
- edge classification
- link prediction
- Graph-level
- graph classification
training方法
- Semi-supervised learning for node-level classification. Given a single network with partial nodes being labeled and others remaining unlabeled
一部分节点有标记,一部分训练... - Supervised learning for graph-level classification,一通操作对图进行分类
- Unsupervised learning for graph embedding. 没有class label的时候,生成graph embedding的法子
但,要graph embedding的动机是什么,如果是graph level的task,只有上面提到的 graph-level classification,是为了其他的吗 → ai说可以作为其他下游任务的output,如「通过比较嵌入向量来执行节点相似性或社群检测」
Recurrent Graph Neural Networks
略,老古董了
Convolutional Graph Neural Networks
分类:
- Spectral-based approaches define graph convolutions by introducing filters from the perspective of graph signal processing where the graph convolutional operation is interpreted as removing noises from graph signals.
怪不得有论文说什么信号什么filter,是这类工作的延伸
以及有人和我说diffusion也是去噪云云 - Spatial-based approaches inherit ideas from RecGNNs to define graph convolutions by information propagation.
- Since GCN bridged the gap between spectral-based approaches and spatial-based approaches, spatial-based methods have developed rapidly recently due to its attractive efficiency, flexibility, and generality.
所以GCN在方法论上大一统...
focus Spatial-based ConvGNNs和后面
MPNN: outlines a general framework of spatial-based ConvGNNs,不同的U, M, R(readout,给下游任务用的) 函数可以组合成实际存在的一堆GNN
J. Gilmer, S. S. Schoenholz, P. F. Riley, O. Vinyals, and G. E. Dahl, “Neural message passing for quantum chemistry,” in Proc. of ICML, 2017, pp. 1263–1272.
然后hidden state提供给下游任务...
GIN
- motivation:基于 MPNN 的方法无法根据它们产生的图嵌入来区分不同的图结构
- add 一个可学习的参数来调整中心节点的权重
怎么理解,这个参数到底如何可学习,到底表示什么
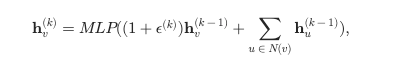
GraphSAGE
- motivation:邻域节点过多
- 对每个节点,采样固定数量的邻居,进行卷积,公式中的S意味着采样
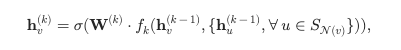
GAT - motivation:不同节点对中心节点的贡献不同,也非预先确定
- 用注意力机制来学习两个连接节点之间的相对权重
其中
然后对它leakyrelu+softmax,得到最终分数
有一堆后续工作:GAAN/GeniePath...
Mixture Model Network (MoNet) adopts a different approach to assign different weights to a node’s neighbors
坏了,这个idea似乎有人做过类似的,但比较老...翻新一下
施工分界线