先前将 MoE 的内存密集型专家参数卸载到 CPU 内存的解决方案不足,因为从 CPU 迁移激活专家到 GPU 的延迟会导致高性能开销。我们提出的预门控 MoE 系统通过我们的算法-系统协同设计,有效解决了传统 MoE 架构的计算和内存挑战。 预门控 MoE 采用我们新颖的预门控功能,缓解了稀疏专家激活的动态特性,使我们的系统能够解决 MoE 的大内存占用问题,同时实现高性能。我们证明预门控 MoE 能够提升性能、减少 GPU 内存消耗,同时保持相同的模型质量。这些特性使我们的预门控 MoE 系统能够以高性价比的方式,仅使用单个高性能 GPU 部署大规模 LLMs。
intro
moe当前的问题
- expert内存开销 → 多卡部署
- dynamic sparse activation of expert → 低计算利用率
- 先前的工作:moe offload → lantency,下降服务质量,这是因为没有解决bound,aka专家选择 → 专家推理的串行顺序
提出软硬协同的优化办法
- 算法:消除专家选择 → 专家推理的串行顺序
- 系统:仍然offload,但预取仅激活的专家到 GPU
实验:NLP系列任务,增加了 23% 性能开销,但减少内存消耗 4.2×
方法
算法层面
简单来讲,每个pregate layer给下一个moe模块选择激活

和之前看的一篇kv cache(infigen)操作一摸一样,有 skip connection,提前给下一层所需信息...
但还有细节问题需要解决:第一个/最后一个怎么办,细节见图:
- 第一个layer单独有个first gate控制本层 expert激活
- 最后一个layer没有pregate

那么怎么训练这个pregate?
- 用已有参数修改
- 根据下游任务微调,精度不受影响
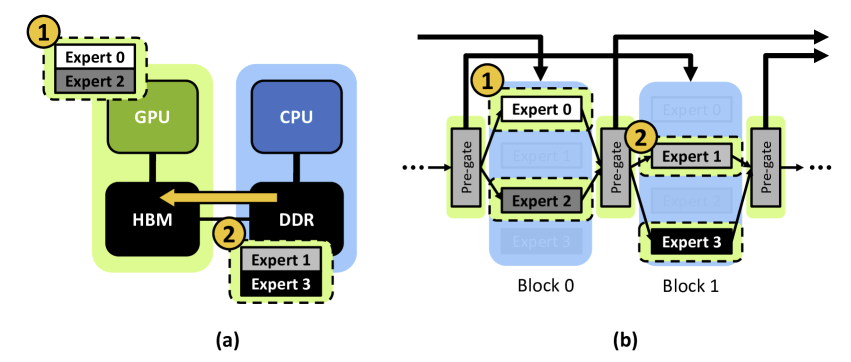
系统层面

蓝色 selection stage和 绿色 execution stage有依赖,而的 Pre-gated MoE 使计算受限的专家执行阶段(绿色)能够与通信受限的专家选择阶段(蓝色)并发执行所有 MoE 模块

pregate moe中,expert的激活迁移 和 推理 流水线并行,推理02的时候,加载13

与其他Expert 迁移技术对比
- 之前的CPU Offload技术
- 【没有和其他操作并行】CPU 卸载的专家参数迁移延迟要么直接作为端到端推理时间的一部分暴露(MoE-OnDemand)
- 【迁移全部下一层 expert】要么迁移的专家大小太大,尽管有机会将专家迁移与专家执行重叠,但复制专家会压倒端到端性能(MoE-Prefetch)
- 使用最小的专家迁移开销进行 CPU 卸载,即仅迁移下一个 MoE 块的激活专家,同时当前 MoE 块的专家正在执行