水平:NeurIPS Poster
拷打记录:Graph Mixture of Experts: Learning on Large-Scale Graphs with Explicit Diversity Modeling | OpenReview
intro
motivation:能否在不影响其推理效率的情况下有效地扩展 GNN 模型的能力以利用更大规模、更多样化的图数据?
和general的moe动机一样
许多 GNN 架构的一个常见限制是它们在整个图中本质上是 “同质的”,即强制所有节点共享相同的聚合机制,而不管它们的节点特征或邻域信息如何。 1 当对不同的图形结构进行训练时,这可能是次优的,例如,当一些节点可能需要在较长范围内聚合信息,而另一些节点则更喜欢较短距离的局部信息时。我们的解决方案是提出了一种新颖的 GNN 架构,称为 Graph Mix of Experts (GMoE)。它由每一层的多个 “专家” 组成,每个专家都是一个独立的消息传递函数,具有自己的可训练参数。这个想法为解决图形数据中存在的多样性挑战建立了一个新的基础。
tldr:对不同的节点,做不同的信息聚合,aka「GMoE 旨在智能地选择为每个节点量身定制的聚合专家」
结果
在 OGB 基准内对 10 个图学习数据集进行的广泛实验证实了我们方法的有效性。例如,与单专家基线相比,GMoE 通过在 1.81% ogbg-molhiv 、 1.40% ogbg-molbbbp、 0.95% ogbn-protein 上增强 ROC-AUC,并在 ogbl-ddi 上提高 Hits@20 分数 0.89% 。
看看怎么说实验,它的一个表格上都是小图二元分类(我扔硬币都50%准确率),这不好
related work
【MoE in GNN,更general的综述】
在图分析领域,先前的研究通过组合具有不同范围的各种 GNN 来收集来自多个范围的知识,类似于固定权重的专家混合 (MoE)。开创性的努力还研究了 MoE 在解决众所周知的不平衡问题和开发无偏分类或泛化算法方面的应用。然而,这些方法都没有利用稀疏性和适应性的潜在优势。最近的工作介绍了使用专家混合进行分子性质预测。
36~39,上古稠密的moe,pass
40 使用 GNN 作为特征提取器,并在提取的特征之上应用混合专家,其中每个专家都是一个线性分类器,用于图形分类。相比之下,GMoE 的每一层都构成了专家的混合体,每个专家体都是一个具有不同聚集步长的 GCN/GIN 层。与40的另一个区别在于,它们利用特定领域的知识(特别是分子拓扑结构)进行专家路由,而我们的方法旨在对一般图进行作,而不依赖于特定领域的假设。41 的另一项同时进行的研究采用 MoE 来实现 GNN 预测的公平性。
Liguang Zhou, Yuhongze Zhou, Tin Lun Lam, and Yangsheng Xu. CAME: Context-aware mixture-of-experts for unbiased scene graph generation. arXiv preprint arXiv:2208.07109, 2022.
Suyeon Kim, Dongha Lee, SeongKu Kang, Seonghyeon Lee, and Hwanjo Yu. Learning topology-specific experts for molecular property prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 8291–8299, 2023.
自称novelty:
- 用不同GCN/GIN 搞MoE
- 泛化
【Adapting Deep Architectures for Training Data Diversity】
如何增强通用深度神经网络的能力,以有效利用各种训练样本,而不会产生额外的推理成本,这里说的都是CNN啊,感觉是凑数的,不管这部分
method
GMoE公式
- 左边是1 hop expert,右边是 2 hop expert
表示 i之间的消息函数 ,可以是GCN, GIN...,参数有: 表示node i 到 node j的消息 - hi? node feature
- G 是 gating function,生成多个decision scores
用noisy top-k gating,这个是它提到的老论文方法
loss function
这部分和其他GNN模型很不一样?
用expectation-maximization loss → 模型只选择一组专家,怎么缓解,两个法子:
衡量了重要性分数的变化,迫使所有专家都“同样重要” - load-balanced loss:「here may still be disparities in the load assigned to different experts」「one expert could receive a few high scores, while another might be selected by many more nodes ye t all with lower scores」(我的理解是,有的expert数据偏向高分,有的偏向低分,这可能不好?) ⇒ an additional load-balanced loss to encourage a more even selection probability per expert
Computational Complexity Analysis
- 分析了一堆,就是证明它和原本的GNN推理时间开销没什么区别
- 在实践中,在我们的 NVIDIA A6000 GPU 上,样本的 10,000 推理时间是 30.2±10.6ms 针对 GCN-MoE 和 36.3±17.2ms GCN 的。GPU 时钟时间的微小差异与它们几乎相同的理论 FLOP 一致。
- 你们怎么也是A6000,这是GNN的标准出装吗?
Experimental Results
- Graph Classification
- 四个ogbg的化学小图
- Graph Regression
- ogbg-molesol
- ogbg-molfreesolv
- 也是化学小图...
- Node Prediction
- ogbn-protein,好像是唯一比较大的
- ogbn-arxiv small
- Link Prediction
- ogbl-ppa Medium 少于 300 个节点
- ogbl-ddi small
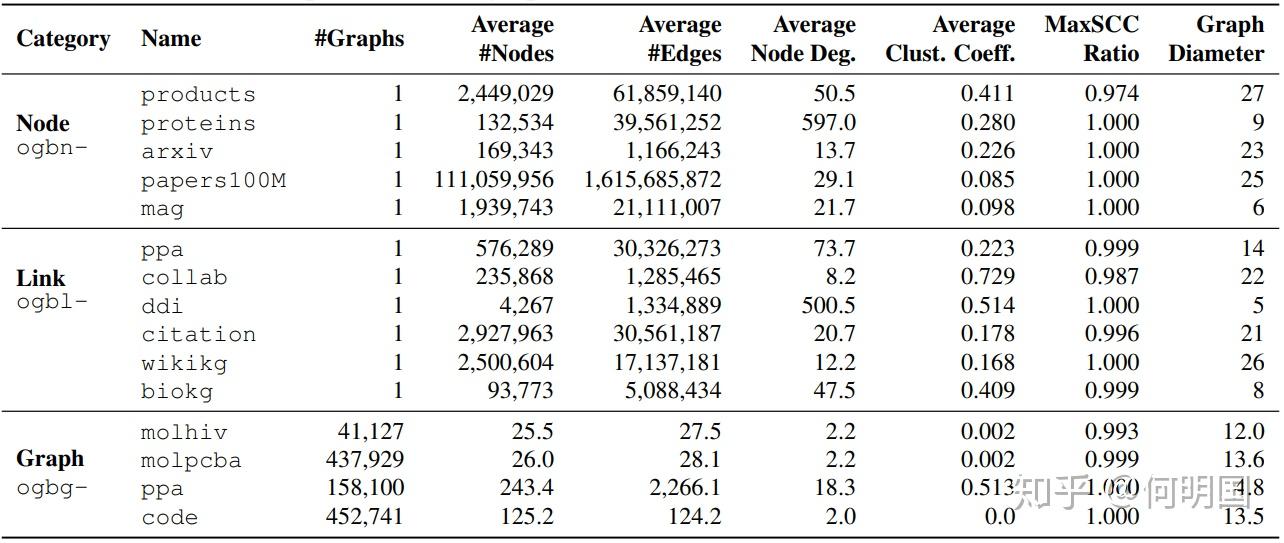
分为 small、medium、large 三个规模,具体为 small:超过 10 万个节点和超过 100 万条边;medium:超过 100 万个节点或超过 1000 万条边;large:大约 1 亿个节点或 10 亿条边。
啊,但化学的没多少节点啊...